Podrobnosti o existující statistice je možné zjistit v
- SSMS – Object Explorer – statistics – properties – Details.
- systémových pohledech sys.stats a sys.stats_columns
- DBCC SHOW_STATISTICS(<table_name>, <stats_name>) [WITH HISTOGRAM]
Co statistika obsahuje?
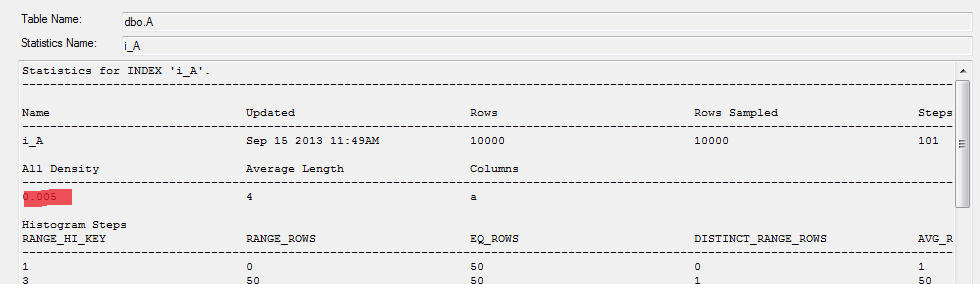
All Density – 1 / (počet jedinečných hodnot)
Statistika má maximálně 200 řádků.
Řádek statistiky obsahuje:
- RANGE_HI_KEY – Horní mez intervalu kroku histogramu.
- RANGE_ROWS – počet řádků v intervalu, mimo horní mez
- EQ_ROWS – počet řádků odpovídající horní mezi intervalu
- DISTINCT_RANGE_ROWS – počet jedinečných hodnot v intervalu, mimo horní mez
- AVG_RANGE_ROWS – průměrná hodnota počtu jedinečných hodnot, mimo horní mez. Tedy RANGE_ROWS / DISTINCT_RANGE_ROWS
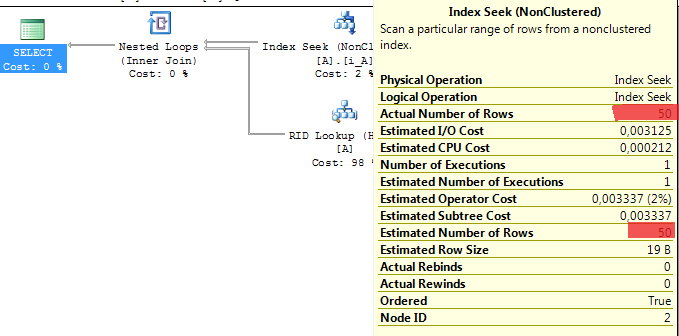
Pokud v exekučním plánu vidíme velmi rozdílnou hodnotu v údaji Estimated Number of Rows a Actual Number of Rows, pak máme problém se statistikami.
Pokud je na úrovni SQL serveru zapnuto Auto Create Statistics a Auto Update Statistics (a tyto hodnoty by měly být zapnuty), pak pokud server při vytváření exekučního plánu zjistí chybějící statistiky respektive zastaralé statistiky, tak dojde k vytvoření potřebné statistiky respektive k občerstvení zastaralé statistiky. To může zdržovat při vykonávání dotazu. Odchytit update statistik při vykonání dotazu je možné Profilerem – událost Performance/Auto Stat.
Při rebuildu indexu dojde k aktualizaci statistik s ním spojených. V tomto případě se provede fullscan, tedy statistiky se vypočtou ze všech řádků a dostaneme tak nejpřesnější možné statistiky. Po tomto není vhodné aktualizovat statistiky s implicitním nastavením, výsledek by byl horší než při použití fullscan.
Server automaticky (pokud je zapnuto Auto Create Statistics) vyrábí statistiky, které potřebuje pro vytvoření plánu vykonávání dotazu. Statistiky vyrábí jen pro jednotlivé sloupce. Automaticky není schopen vyrobit statistiky pro kombinací sloupců. V určitých případech může být vhodné takovéto statistiky vytvořit manuálně, nebo za použití Database Tuning Advisor.
Filtrované statistiky
S vytvořením filtrovaného indexu se vytvoří i filtrovaná statistika.
Filtrované statistiky je možné vytvářet i manuálně.
Výhodou je možnost obejít limit 200 řádků statistiky tak, že vytvoříme dvě statistiky v různých intervalech hodnot. Například jednu pro 90% historických dat a jednu podrobnější pro 10% aktuálních a často používaných dat.
Nevýhodou je, že pokud používáme filtrované statistiky nad sloupcem a pokud server zjistí, že chybí nefiltrovaná statistika, pak nefiltrovanou statistiku automaticky vytvoří. S tím souvisí režie s udržováním dvojích statistik. Doporučuje se ponechat zapnuté automatické tvoření statistik a u nefiltrované statistiky vypnout automatický přepočet (nastavit NORECOMPUTE) a nechat ji zestárnout, server pak bude používat aktuální filtrované statistiky.
Automatický update statistik
Řídí se nastavením serveru:
Auto Update Statistics – zapíná automatickou aktualizaci
Auto Update Statistics Asynchronously – zapíná asynchronní aktualizaci statistik, implicitně vypnuto
Synchronní aktualizace – Pokud se při sestavování plánu zjistí zastaralá statistika, pak se okamžitě provede její aktualizace. Výhodou je plán na základě vždy aktuálních statistik. Nevýhodou je, že aktualizace statistik zdržuje sestavení plánu. Toto nastavení se doporučuje.
Asynchronní aktualizace – Plán se sestaví na základě dostupných statistik. Pokud se zjistí zastaralá statistika, pak je asynchronně odpálena její aktualizace. Výhodou je, že sestavení plánu není zdržováno výpočtem statistik. Nevýhodou je, že plán může být postaven na základě neaktuálních statistik.
Statistiky jsou zastaralé když
- tabule má více než 500 řádků a je modifikováno více než 20% řádků + další 500 řádků
- tabule má méně nebo rovno 500 řádků a je modifikováno 500 řádků
- pokud se počet řádků tabule změní z 0 na nenulový počet
- u temporarních tabulí po každých změněných 6 záznamech
Filtrované statistky se vyhodnocují bohužel podle počtu modifikací všech řádků a ne jen těch řádků zahrnutých do filtru. Z toho vyplývá nutnost manuální aktualizace filtrovaných statistik.
Zda jsou statistiky zastaralé se vyhodnocuje při sestavování plánu vykonání dotazu.
Chybějící statistiky
Je možné odhalit profilerem zachycením události Errors and Warnings/Missing Column Statistics
Příčinou může být vypnutá volba serveru Auto Create Statistics.
Druhou příčinou může být používání tabulkových proměnných pro které server statistiky nevyrábí (odhadovaný počet řádků je vždy 1 respektive 0 při nesplnitelné podmínce). Mělo by být pravidlem, že tabulkové proměnné se používají jen pro tabulky do 100 řádků. Pro větší tabulky je lépe využívat temporární tabuli (s ‚#‘ na začátku názvu).
Nemožnost použít statistiky
Při použití proměnných v podmínkách výběru nemůže server vyžít statistiky, protože nezná hodnotu proměnné v době sestavování plánu. Pro odhadovaný počet řádků tak server použije průměrnou hodnotu z celé tabulky, která se může diametrálně lišit od hodnoty odpovídající hodnotě proměnné, můžeme tak dostat chybný plán vykonání.
Příliš hrubé statistiky
Pro 4 000 000 záznamů dostaneme 200 řádků statistiky po 20 000 záznamech. Z toho může být 90% historických dat, pro které se statistiky nemění. Řešením je udělat dvě statistiky. Jednu pro historická data, tu není potřeba často udržovat. A jednu pro aktuální živá data. Statistika pro 10% živých dat tak bude jemněji dělena a bude muset být manuálně častěji udržována aktuální.
Nedostatečné automatické aktualizace
20% modifikovaných řádků je málo pro odpálení automatické aktualizace u tabulí s velkým počtem řádků. Nejhorší je to u primárních klíčů, které přibývají na konci řady, tedy mimo statistku a server je tak nemůže vyhodnotit. Zde je nutná častější manuální aktualizace statistiky.
Statistiky a paměť
Statistiky jsou používány pro odhad velikosti potřebné paměti pro některé druhy joinu. Pokud je odhad podhodnocen, pak je místo chybějící paměti využívána tempdb a dochází k cca 10 násobnému zpomalení. Tento problém je možné zachytit profilerem jako události Errors and Warnings/Sort Warnings a Errors and Warnings/Hash Warnings
Zdroje
SQL Server Statistics