
Pojďme se podívat, co dělá query optimizer, když mu zabráníme používat statistiky.
Nejdříve si připravme tabulku pro testy a naplňme jí daty.
CREATE TABLE A(a INT, b CHAR(500)) GO SET NOCOUNT ON DECLARE @o INT = 1 DECLARE @p INT = 1 WHILE @o <= 50 BEGIN WHILE @p <= 200 BEGIN INSERT INTO A(a,b) VALUES(@p,'x') SET @p += 1 END SET @p = 1 SET @o += 1 END GO
Vytvoříme index, přičemž se nám vytvoří také statistika na základě všech hodnot ve sloupci a.
CREATE INDEX i_A ON A(a) GO
Nyní vyzkoušíme jak SQL server pracuje, když může statistiky využít. U následujících dotazů na základě statistik server přesně odhadne počet vrácených řádků, což si můžeme ověřit v exekučním plánu.
--odhaduje 50 řádků, vrací 50 řádků SELECT * FROM A WHERE a = 50 --odhaduje 500 řádků, vrací 500 řádků SELECT * FROM A WHERE a <= 10 --odhaduje 1000 řádků, vrací 1000 řádků SELECT * FROM A WHERE a <= 20 --odhaduje 3000 řádků, vrací 3000 řádků SELECT * FROM A WHERE a <= 60 --odhaduje 150 řádků, vrací 150 řádků SELECT * FROM A WHERE a BETWEEN 1 AND 3
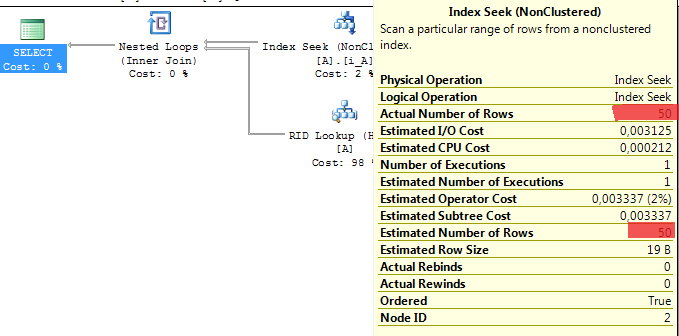
Pokud však místo konstanty v podmínce výběru použijeme proměnné, pak server v době kompilace dotazu nezná jejích hodnotu a nemůže podle statistiky tedy odvodit počet vrácených řádků. Server v tomto případě počty vrácených řádků odhaduje na základě použitého operátoru v podmínce a to nezávisle na hodnotě proměnné.
--odhaduje 50 řádků, vrací 50 řádků DECLARE @a INT = 50 SELECT * FROM A WHERE a = @a GO --odhaduje 50 řádků, vrací 0 řádků DECLARE @a INT = 500 SELECT * FROM A WHERE a = @a GO --odhaduje 3000 řádků, vrací 500 řádků DECLARE @a INT = 10 SELECT * FROM A WHERE a <= @a GO --odhaduje 3000 řádků, vrací 1000 řádků DECLARE @a INT = 20 SELECT * FROM A WHERE a <= @a GO --odhaduje 3000 řádků, vrací 3000 řádků DECLARE @a INT = 60 SELECT * FROM A WHERE a <= @a GO --odhaduje 3000 řádků, vrací 0 řádků DECLARE @a INT = 200 SELECT * FROM A WHERE a > @a GO --odhaduje 900 řádků, vrací 150 řádků DECLARE @a INT = 1 DECLARE @b INT = 3 SELECT * FROM A WHERE a BETWEEN @a AND @b
Pojďme si vysvětlit jak k takovým odhadům server dojde. Sloupec a obsahuje 10 000 hodnot a 200 jedinečných hodnot. Statistika i_A obsahuje hodnotu All density, která se vypočte jako 1 / počet jedinečných hodnot, tedy v našem případě 1 / 200 = 0.005.
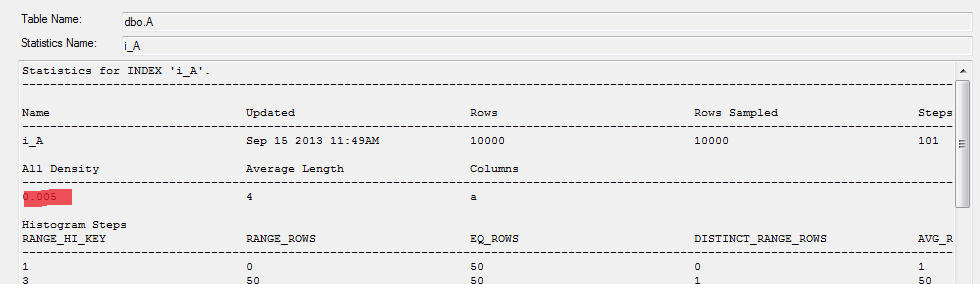
Pro operátor rovnosti server odhaduje počet vrácených řádků jako All density * počet řádků. V našem případě 0.005 * 10 000 = 50.
Pro operátory >, <, >=, <= odhaduje počet vrácených řádků jako 30% z celkového počtu řádků, tedy 0.3 * 10 000 = 3000.
Pro operátor BETWEEN odhaduje server počet vrácených řádků jako 9% z celkového počtu řádků, tedy 0.09 * 10 000 = 900.
Přesně takto kvalitní odhady server používá, pokud vnější proměnné z procedury předáme do vnitřních proměnných a snažíme se tak zamezit parametr sniffingu.