Sql server používá paměť především pro 3 věci:
- Buffer pool – nakešované datové stránky
- Plan cache – nakešované plány vvykonávání dotazu
- Query workspace memory – paměť potřebná pro běh dotazu
Dotaz může pro svůj běh dostat až 25% přidělené paměti SQL serveru. Pokud tedy někomu chcete shodit server a máte práva jen na select, tak stačí souběžně spustit několik dotazů, které si řeknou o pořádnou porci paměti. Případně stačí nechat uživatelům spouštět přes den účetní reporty ![]()
Takovéto dotazy ubírají paměť buffer poolu, tedy SQL server bude muset tahat data z pomalého disku, ubírají paměť plan cache, tedy server zahodí plány a bude žhavit CPU, aby je spočítal znova a dotazy potřebující k běhu paměť se budou stavět do fronty na její přidělení.
Pojďme se podívat na to, jak takové dotazy můžou vypadat.
Nejdříve si vytvoříme tabulku, která bude obsahovat různě dlouhé pole typu VARCHAR. Naplníme ji řádky, ale varcharové pole necháme s hodnotou NULL.
--vytvořím tabulku CREATE TABLE dbo.a( id INT IDENTITY(1,1) NOT NULL CONSTRAINT pk_a PRIMARY KEY CLUSTERED, text100 VARCHAR(100) NULL, text500 VARCHAR(500) NULL, text5000 VARCHAR(5000) NULL, textmax VARCHAR(MAX) NULL ) --naplním tabulku tak, že v ní bude 100 tisíc záznamů a všechny hodnoty NULL INSERT INTO dbo.a(text100) SELECT TOP (100000) NULL FROM sys.all_objects ao CROSS JOIN sys.all_objects ao2 GO
Teď budu spouštět různé dotazy nad tabulkou a sledovat jak SQL server odhaduje náklady na dotaz (Estimated Subtree Cost) a především kolik dotazu přidělí paměti (Memory Grant). Tyto údaje vyčtu v exekučním plánu v properties selectu.
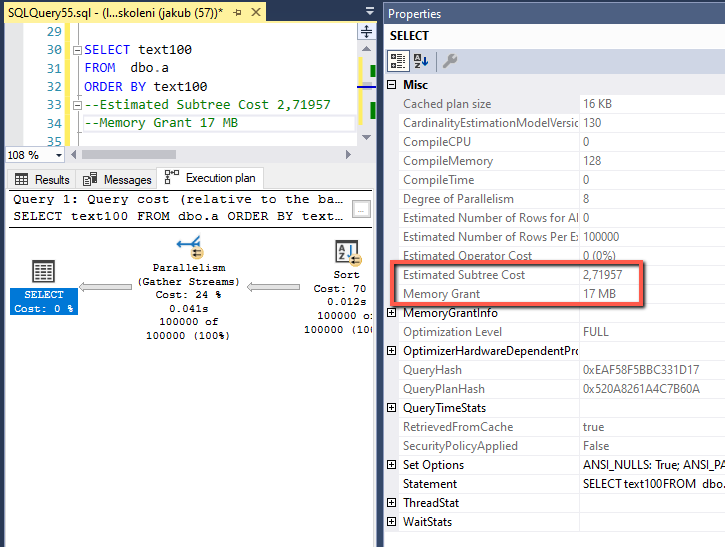
Dosažené hodnoty píšu do komentáře pod selectem.
--Ctrl+M (exekuční plán) SELECT * FROM dbo.a --Estimated Subtree Cost 0,231801 --Memory Grant 0 SELECT textmax FROM dbo.a --Estimated Subtree Cost 0,231801 --Memory Grant 0
Pro SELECT * i SELECT testmax to vypadá bez problémů. Dokud nemáme JOIN, ani ORDER BY, tak dotaz nepotřebuje paměť. Přidejme tedy ORDER BY.
SELECT text100 FROM dbo.a ORDER BY text100 --Estimated Subtree Cost 4,78899 --Memory Grant 14 MB SELECT text500 FROM dbo.a ORDER BY text100 --Estimated Subtree Cost 5,68254 --Memory Grant 44 MB SELECT text5000 FROM dbo.a ORDER BY text100 --Estimated Subtree Cost 197,926 --Memory Grant 313 MB SELECT textmax FROM dbo.a ORDER BY text100 --Estimated Subtree Cost 578,555 --Memory Grant 495 MB SELECT * FROM dbo.a ORDER BY text100 --Estimated Subtree Cost 588,143 --Memory Grant 824 MB
Tady už to bylo zajímavější. Je z toho vidět, že čím větší datové typy se používají, tím víc paměti si dotaz vezme. Stejně tak, čím víc sloupců dotaz vrací, tím hůř. Datové typy by tedy měly být co možná nejmenší a select by měl vracet jen potřebné sloupce. Připomínám, že všechny sloupce v tabulce mají hodnotu NULL. SQL server vlastně nic neseřazoval, ani žádná data nevracel. Podle velikosti datových typů si odhadl kolik paměti bude potřebovat pro setřízení a tuto paměť zabral, i když ji měl nakonec k ničemu. Poslední dotaz se blížil 1GB paměti a to šlo jen o 100 tisíc řádků. Nad většími daty není problém zabrat gigabajty paměti a vypláchnout tak buffer pool. Nejde ani tak o to, že by tyto dotazy byly pomalejší, spíše se tím zpomalují ostatní dotazy, které budou muset tahat data z disku. Vlastně se tak snižuje výkon celého SQL serveru.
Ještě si ukážeme rozdíl mezi SELECT TOP 100 a SELECT TOP víc než 100
SELECT TOP 101 * FROM dbo.a ORDER BY text100 --Estimated Subtree Cost 563,9 --Memory Grant 824 MB SELECT TOP 100 * FROM dbo.a ORDER BY text100 --Estimated Subtree Cost 563,9 --Memory Grant 4 MB DROP TABLE dbo.a
Pokud je TOP vetší než 100, tak si server pro setřízení alokuje stejnou paměť jako by tam žádný TOP nebyl. Pokud je TOP 100 a méně, tak se použije jiný typ setřízení a ušetří se násobky paměti. U mě 824 MB : 4 MB. To je 206 krát méně. U větších dat bude rozdíl ještě větší. Pokud používáme TOP, tak nejlépe do hodnoty 100.