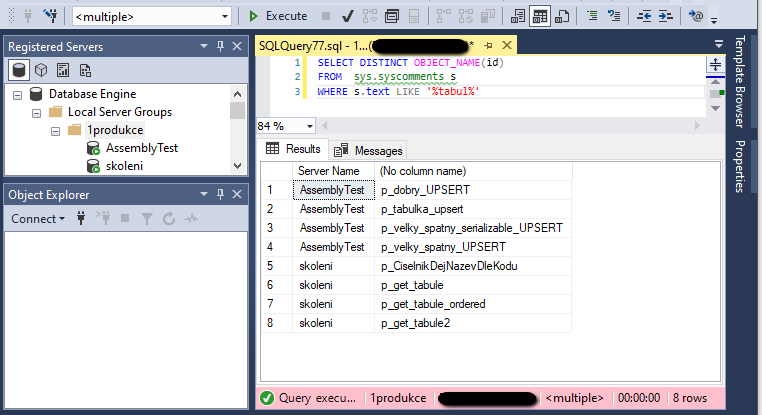
Pro JSON není v SQL serveru spciální datový typ. Používá se NVARCHAR(MAX), JSON formát můžu vynutit constraintem pomocí funkce ISJSON.
Jako přiklad si udělám tempovou tabulku s constraintem
CREATE TABLE #json( JSONData NVARCHAR(MAX) NOT NULL CONSTRAINT check_JSONData_is_json CHECK (ISJSON(JSONData) = 1) ) GO
Pokusím se vložit něco, co není JSON
INSERT INTO #json(JSONData) VALUES('nesmysl')
GO
--The INSERT statement conflicted with the CHECK constraint "check_JSONData_is_json". The conflict occurred in database "tempdb", table "dbo.#json_______________________________________________________________________________________________________________000000000067", column 'JSONData'.
Založím testovací data
INSERT INTO #json(JSONData) VALUES(
N'
[
{
"jmeno": "Kamil",
"prijmeni": "Skočdopole",
"konicky": [
"šachy",
"sport",
"vážná hudba"
],
"adresy": [
{
"typ": "bydliště",
"mesto": "Frenštát pod Radhoštěm",
"cp": "10"
},
{
"typ": "doručovací",
"mesto": "Ostrava",
"cp": "50"
}
],
"hodne pije": true,
"telesna_teplota": 36.9,
"zbrojni_pas":null
},
{
"jmeno": "Uršula",
"prijmeni": "Králová",
"konicky": [
"pletení",
"ultramaraton"
],
"adresy": [
{
"typ": "bydliště",
"mesto": "Frenštát pod Radhoštěm",
"cp": "10"
}
]
}
]
'
)
SELECT * FROM #json
Otestování, zda máme validní JSON
SELECT ISJSON((SELECT * FROM #json))--vrací 1
JSON_QUERY vrací JSON objekt, nebo pole
SELECT JSON_QUERY((SELECT * FROM #json)) SELECT JSON_QUERY((SELECT * FROM #json), '$[0].adresy') SELECT JSON_QUERY((SELECT * FROM #json), '$[1].adresy') SELECT JSON_QUERY((SELECT * FROM #json), '$[1].konicky')
Striktní vs. laxní mód
By deafault je laxní
--NULL, protoze jmeno je hodnota a ne objekt SELECT JSON_QUERY((SELECT * FROM #json), '$[0].jmeno') --NULL, protoze jmeno je hodnota a ne objekt SELECT JSON_QUERY((SELECT * FROM #json), 'lax $[0].jmeno') --Object or array cannot be found in the specified JSON path. SELECT JSON_QUERY((SELECT * FROM #json), 'strict $[0].jmeno')
JSON_VALUE vrací hodnotu NVARCHAR(4000)
SELECT JSON_VALUE((SELECT * FROM #json), '$[0].jmeno')--Kamil
Pokud je v názvu atributu mezera, tak ho musím mít v uvozovkách
--JSON path is not properly formatted. Unexpected character ' ' is found at position 10. SELECT JSON_VALUE((SELECT * FROM #json), '$[0].hodne pije') --true SELECT JSON_VALUE((SELECT * FROM #json), '$[0]."hodne pije"')
Neexistující atribut je problém rozeznat od atributu s NULL hodnotou
--NULL SELECT JSON_VALUE((SELECT * FROM #json), '$[0].neexistujici') --Property cannot be found on the specified JSON path. SELECT JSON_VALUE((SELECT * FROM #json), 'strict $[0].neexistujici')
Atribut s NULL hodnotou
--NULL SELECT JSON_VALUE((SELECT * FROM #json), '$[0].zbrojni_pas') --NULL SELECT JSON_VALUE((SELECT * FROM #json), 'strict $[0].zbrojni_pas')
OPENJSON
Další možností čtení JSONu je s použitím funkce OPENJSON. Umožňuje přečíst více než 4000 znaků a vracet data v tabulkové podobě.
Syntaxe je:
OPENJSON( jsonExpression [ , path ] ) [ <with_clause> ]
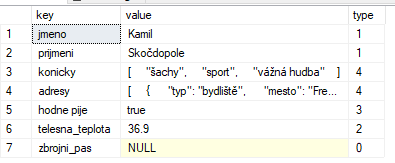
SELECT * FROM OPENJSON((SELECT * FROM #json))
Výsledkem je tabulka se sloupci key, value, type

- key
- název atributu, nebo pořadové číslo v poli
- value
- hodnota
- type
-
0 NULL Rozumná cesta jak rozlišit hodnotu NULL od neexistujícího atributu
1 string
2 číslo
3 boolean
4 pole
5 objekt
Dá se k tomu doplnit cesta
SELECT * FROM OPENJSON((SELECT * FROM #json),'$[0]')
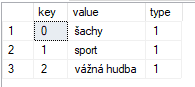
SELECT * FROM OPENJSON((SELECT * FROM #json),'$[0].konicky')
Doplněním WITH kluzule uděláme z JSON tabulku, kde budou atributy ve sloupcích
Syntaxe:
<with_clause> ::= WITH ( { colName type [ column_path ] [ AS JSON ] } [ ,...n ] )
SELECT * FROM OPENJSON((SELECT * FROM #json)) WITH( jmeno NVARCHAR(50), prijmeni NVARCHAR(50), [hodne pije] BIT, nesmysl NVARCHAR(50), zbrojni_pas BIT )
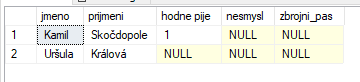
Můžeme doplnit column_path a přejmenovat si na vlastní colName
SELECT * FROM OPENJSON((SELECT * FROM #json)) WITH( jmeno NVARCHAR(50) '$.jmeno', prijmeni NVARCHAR(50) '$.prijmeni', [ochlasta] BIT '$."hodne pije"', nesmysl NVARCHAR(50) '$.nesmysl', zbrojni_pas BIT '$.zbrojni_pas', prvniKonicek NVARCHAR(250) '$.konicky[0]', mesto NVARCHAR(250) '$.adresy[0].mesto' )

Pokud chceme vrátit JSON, nebo pole, tak musíme použít AS JSON, jinak dostaneme NULL
SELECT * FROM OPENJSON((SELECT * FROM #json)) WITH( jmeno NVARCHAR(50) '$.jmeno', prijmeni NVARCHAR(50) '$.prijmeni', [ochlasta] BIT '$."hodne pije"', nesmysl NVARCHAR(50) '$.nesmysl', zbrojni_pas BIT '$.zbrojni_pas', adresy1 NVARCHAR(MAX) '$.adresy', --pokud je tam objekt, nebo pole, --tak nevrátí nic v lax modu. strict by spadnul adresy2 NVARCHAR(MAX) '$.adresy' AS JSON --je potřeba použít AS JSON )

Vrácený JSON z první funkce můžeme dál rozebrat pomocí APPLY OPENSJON
SELECT * FROM OPENJSON((SELECT * FROM #json)) WITH( jmeno NVARCHAR(50) '$.jmeno', prijmeni NVARCHAR(50) '$.prijmeni', [ochlasta] BIT '$."hodne pije"', nesmysl NVARCHAR(50) '$.nesmysl', zbrojni_pas BIT '$.zbrojni_pas', adresy NVARCHAR(MAX) '$.adresy' AS JSON )pole OUTER APPLY OPENJSON(pole.adresy) WITH( typ NVARCHAR(50) , mesto NVARCHAR(50) , cp NVARCHAR(50) )