Jako parametr sniffing se označuje chování SQL serveru, kdy při prvním spuštění procedury server očichá hodnoty vstupních parametrů a na jejich základě postaví exekuční plán, který pak používá při každém dalším spuštění procedury. Ve většině případů je to v pořádku. Ušetří se čas na sestavování exekučního plánu. Pokud však máme proceduru, která na základě různých vstupních parametrů vrací tak rozdílné sady výsledků, že by zasloužily i rozdílné exekuční plány, pak máme problém. Prozkoumal jsem pár možností jak přesvědčit server sestavit odpovídající exekuční plán.
Nejdříve si vytvoříme podkladovou tabulku s daty.
CREATE TABLE tabule(
id INT IDENTITY(1,1) CONSTRAINT pk_tabule PRIMARY KEY,
data NVARCHAR(max) NULL,
a INT
)
--vygeneruji 200 000 záznamů,
--sloupec [a] naplním náhodným číslem s maximální hodnotou 10 000
DECLARE @counter INT
SET @counter = 0
WHILE @counter < 200000
BEGIN
PRINT @counter
INSERT INTO tabule (a) SELECT CAST(RAND() * 10000 AS INT)
SET @counter+=1
END
--naplním tabulku daty, aby bylo bolestivé číst celý clusterovaný index
UPDATE tabule SET data = N'
0123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789
0123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789
0123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789
0123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789
0123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789
0123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789
0123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789
0123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789
0123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789
0123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789'
--vytvořím index na sloupci [a]
CREATE INDEX ix_tabule_a ON tabule(a)
Na jednoduchých dotazech si ověřím, který přistup je nejoptimálnější.
SELECT * FROM tabule WHERE 1 < a AND a < 10
--Table 'tabule'. Scan count 1, logical reads 452, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
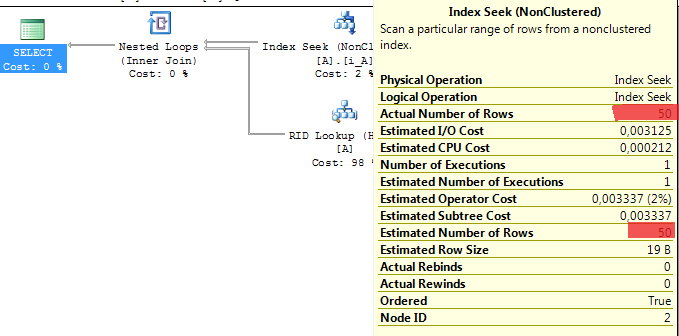
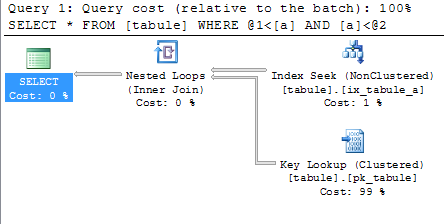
V prvním případě jsem se snažil načíst pouze malou část tabulky. Server optimálně použil index seek nad indexem ix_tabule_a pro vyhledání záznamů vyhovujících podmínce a následně key lookup pro načtení zbylých dat tabulky. Server k tomu potřeboval 452 logických čtení.
SELECT * FROM tabule WHERE 1 < a AND a < 10000
--Table 'tabule'. Scan count 1, logical reads 99845, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
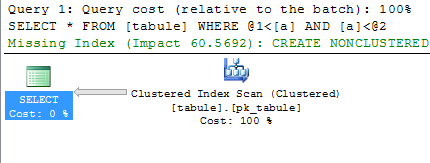
Ve druhém případě chceme vrátit velké množství dat. Server optimálně zvolil index scan nad indexem primárního klíče ze kterého načetl všechna data. Server k tomu potřeboval 99845 logických čtení.
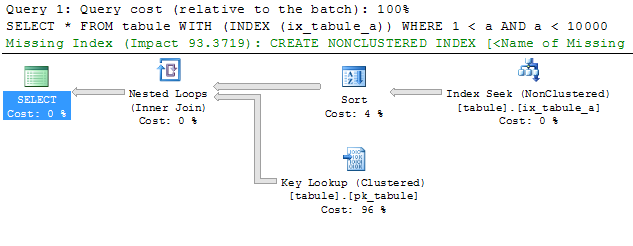
SELECT * FROM tabule WITH (INDEX (ix_tabule_a)) WHERE 1 < a AND a < 10000
--Table 'tabule'. Scan count 1, logical reads 612740, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Ve třetím pokusu se serveru snažím vnutit index seek nad indexem ix_tabule_a pro načtení všech dat. Z počtu logických čtení (612740) opravdu vidíme, že tento přístup je několikanásobně horší než přístup předchozí.
Konečně vytvoříme několik procedur, kde každá bude používat jiný přístup k problému.
IF OBJECT_ID('p_sniff1') IS NOT NULL
DROP PROCEDURE [dbo].[p_sniff1]
GO
--klasicky parametr sniffing
CREATE PROCEDURE [dbo].[p_sniff1]
@a INT,
@b INT
AS
BEGIN
SELECT * FROM tabule WHERE a > @a AND a < @b
END
GO
IF OBJECT_ID('p_sniff2') IS NOT NULL
DROP PROCEDURE [dbo].[p_sniff2]
GO
--vnitrni promenne
CREATE PROCEDURE [dbo].[p_sniff2]
@a VARCHAR(30),
@b VARCHAR(30)
AS
BEGIN
DECLARE @_a VARCHAR(30)
DECLARE @_b VARCHAR(30)
SET @_a = @a
SET @_b = @b
SELECT * FROM tabule WHERE a > @_a AND a < @_b
END
GO
IF OBJECT_ID('p_sniff3') IS NOT NULL
DROP PROCEDURE [dbo].[p_sniff3]
GO
--skladany dotaz
CREATE PROCEDURE [dbo].[p_sniff3]
@a INT,
@b INT
AS
BEGIN
DECLARE @prikaz NVARCHAR(max)
SET @prikaz = 'SELECT * FROM tabule WHERE a > '+CAST(@a AS VARCHAR(30))+' AND a < '+CAST(@b AS VARCHAR(30))
PRINT @prikaz
EXEC(@prikaz)
END
GO
IF OBJECT_ID('p_sniff4') IS NOT NULL
DROP PROCEDURE [dbo].[p_sniff4]
GO
--WITH RECOMPILE
CREATE PROCEDURE [dbo].[p_sniff4]
@a INT,
@b INT
WITH RECOMPILE
AS
BEGIN
SELECT * FROM tabule WHERE a > @a AND a < @b
END
GO
Pak procedury spustíme s následujícími parametry.
EXEC p_sniff1 @a = 1, @b = 10000--index scan nad pk_tabule
--Table 'tabule'. Scan count 1, logical reads 99845, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
EXEC p_sniff1 @a = 1, @b = 10--index scan nad pk_tabule
--Table 'tabule'. Scan count 1, logical reads 99845, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
EXEC p_sniff2 @a = 1, @b = 10000--index seek nad ix_tabule_a + key lookup nad pk_tabule
--Table 'tabule'. Scan count 1, logical reads 612740, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
EXEC p_sniff2 @a = 1, @b = 10--index seek nad ix_tabule_a + key lookup nad pk_tabule
--Table 'tabule'. Scan count 1, logical reads 462, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
EXEC p_sniff3 @a = 1, @b = 10000--index scan nad pk_tabule
--Table 'tabule'. Scan count 1, logical reads 99845, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
EXEC p_sniff3 @a = 1, @b = 10--index seek nad ix_tabule_a + key lookup nad pk_tabule
--Table 'tabule'. Scan count 1, logical reads 461, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
EXEC p_sniff4 @a = 1, @b = 10000--index scan nad pk_tabule
--Table 'tabule'. Scan count 1, logical reads 99845, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
EXEC p_sniff4 @a = 1, @b = 10--index seek nad ix_tabule_a + key lookup nad pk_tabule
--Table 'tabule'. Scan count 1, logical reads 461, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Procedura p_sniff1 používá klasický parametr sniffing. Při prvním spuštění byl sestaven exekuční plán využívající index scan nad pk_tabule, což je správně. Při druhém spuštění se tohoto plánu stále drží a to je problém, protože při výběru pár hodnot by byl výhodnější index seek nad ix_tabule_a.
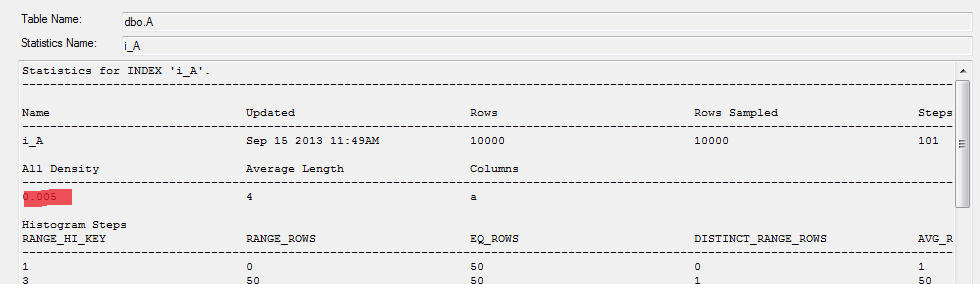
Na internetu je možné najít, že pro řešení problému s parametr sniffingem se dá použít metoda s deklarací vnitřních proměnných v proceduře. Toto zkouším v proceduře p_sniff2. Už ale první spuštění pro celý rozsah sloupce a skončilo s exekučním plánem využívajícím index seek nad indexem ix_tabule_a, což je blbost. Server přečetl index a navíc ještě celou tabuli. Pokud se podíváme na exekuční plán a na tooltip nad ikonou index seek, pak se dozvíme, že Estimated Number of Rows je 18 000 v obou případech a Actual Number of Rows je 199 960 v prvním případě (@a = 1, @b = 10000) a 147 ve druhém případě (@a = 1, @b = 10). Příčinou je, že server nemůže kvůli použití vnitřních proměnných vhodně využít statistiky a učiní tak odhad na základě průměrného počtu jedinečných řádků v celé tabulce. Tento odhad je pro oba případy 18 000 řádků. Na základě tohoto odhadu vybral server index seek. V prvním případě byl tento odhad velmi vzdálen 199 9600 vráceným řádkům a využití index seek bylo naprosto nevhodné. Ve druhém případě i navzdory tomu, že se odhad velmi lišil od hodnoty 147 vybraných řádků bylo použití index seek vhodné. Použití vnitřních proměnných považuji za absolutně nevhodné, protože server nemůže optimálně vyžít statistiky. Více o příčinách v článku Odhady počtu řádků a proměnné. Více o statistikách v článku Statistiky v MSSQL serveru.
Procedura p_sniff3 používá skládaný dotaz. Exekuční plán dostaneme správný pro obě volání. Ve skutečnosti server cachuje plán pro každou kombinaci vstupních parametrů. Je potřeba zvážit, zda je vhodné takto plnit cache.
Procedura p_sniff4 používá hint WITH RECOMPILE, čímž donutí server poskládat správný exekuční plán při každém spuštění procedury. Ztratíme výhodu nacachovaného exekučního plánu, ale zato vždy dostaneme plán správný. Pokud potřebujeme pro různé vstupní parametry procedury různé exekuční plány, přijde mi toto řešení jako ideální varianta.
Pokrývací index
Nutno dodat, že všechny problémy by se zde daly vyřešit pokrývacím indexem, který by byl schopen vrátit všechny požadované sloupce a kde jedinou správnou variantou je index seek nad tímto indexem. Pak odpadá problém, že pro různé vstupy je potřeba různý exekuční plán.
CREATE INDEX ix_tabule_covering ON tabule(a) INCLUDE(data)
EXEC p_sniff1 @a = 1, @b = 10000
--Table 'tabule'. Scan count 1, logical reads 66828, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
EXEC p_sniff2 @a = 1, @b = 10000
--Table 'tabule'. Scan count 1, logical reads 66828, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
EXEC p_sniff3 @a = 1, @b = 10000
--Table 'tabule'. Scan count 1, logical reads 66828, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
EXEC p_sniff4 @a = 1, @b = 10000
--Table 'tabule'. Scan count 1, logical reads 66828, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.