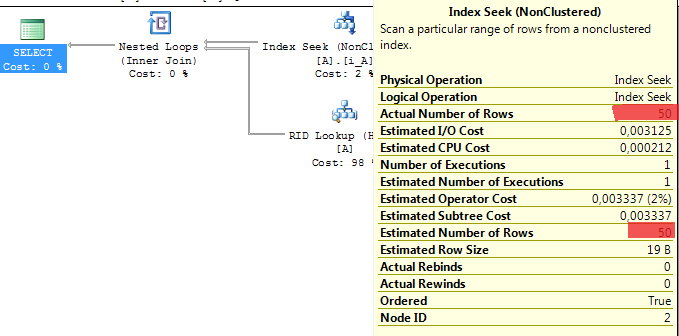
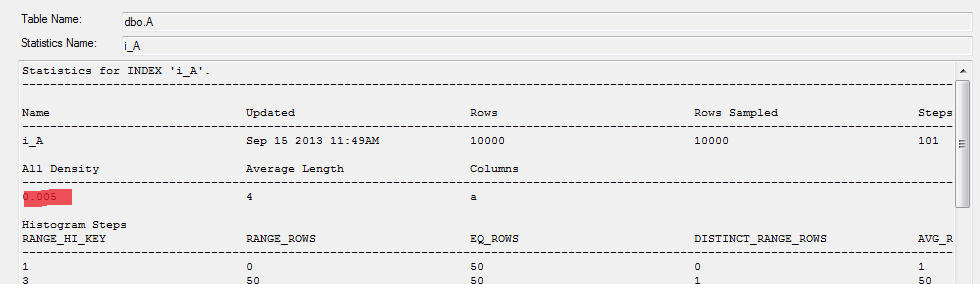
Dohledejme si sloupce, které jsou nullable a vyhovují podmínkám pro řídké (sparse) sloupce.
SELECT s.name [schema], o.name [table], c.name [column], c.is_nullable, c.is_sparse, t.name dataType, c.max_length, 0 nullRows, 0 notNullRows, CAST(0 AS NUMERIC(18,2)) ratio
INTO #sparseCandidate
FROM sys.objects o
JOIN sys.schemas s ON o.schema_id = s.schema_id
JOIN sys.columns c ON c.object_id = o.object_id
JOIN sys.types t ON c.system_type_id = t.user_type_id
WHERE o.type = 'U' --user table
AND c.is_nullable = 1
AND t.name NOT IN ('geography', 'geometry', 'image', 'ntext', 'text', 'timestamp')
AND c.is_sparse = 0
AND c.is_nullable = 1
AND c.is_rowguidcol = 0
AND c.is_identity = 0
AND c.is_computed = 0
AND c.is_filestream = 0
AND c.default_object_id = 0
AND c.rule_object_id = 0
AND NOT EXISTS(--nemuze byt v unikatnim klici ani v clusterovanem indexu
SELECT 1
FROM sys.indexes i
JOIN sys.index_columns ic ON i.object_id = ic.object_id AND i.index_id = ic.index_id
WHERE o.object_id = i.object_id AND c.object_id = ic.object_id AND c.column_id = ic.column_id
AND (
i.is_primary_key = 1
OR i.type = 1 --clustered
)
)
Dohledáme zaplnění sloupců hodnotami.
DECLARE @schema CHAR(100) DECLARE @table CHAR(100) DECLARE @column CHAR(100) DECLARE @command NVARCHAR(MAX) DECLARE crs CURSOR FOR SELECT [schema], [table], [COLUMN] FROM #sparseCandidate OPEN crs FETCH NEXT FROM crs INTO @schema, @table, @column WHILE @@FETCH_STATUS = 0 BEGIN SET @command = ' UPDATE #sparseCandidate SET nullRows = ( SELECT COUNT(*) FROM '+@schema+'.'+@table+' WHERE '+@column+' IS NULL ), notNullRows = ( SELECT COUNT(*) FROM '+@schema+'.'+@table+' WHERE '+@column+' IS NOT NULL ) WHERE [schema] = '''+@schema+''' AND [table] = '''+@table+''' AND [column] = '''+@column+''' ' PRINT @command EXEC (@command) FETCH NEXT FROM crs INTO @schema, @table, @column END CLOSE crs DEALLOCATE crs
Dopočteme poměr.
UPDATE #sparseCandidate SET ratio = CAST( nullRows * 100 / (nullRows + notNullRows) AS NUMERIC(18,2)) WHERE nullRows <> 0 AND notNullRows <> 0
Řekněme, že nás zajímají sloupce s poměrem nad 70%. Tyto sloupce je vhodné nastavit jako sparse a případně doplnit index o filtr na NOT NULL.
SELECT * FROM #sparseCandidate WHERE ratio > 70 ORDER BY ratio DESC